
The evolution of network programming
Thu, 20th Jun 2019
You glide the cursor onto the icon, click and hold, slide it across to the waste bin – and the image, program, or whatever the icon represented, has been deleted. It takes barely second: but how long did it take to program that one simple gesture into the graphical user interface? In the not so distant past it took thousands of lines of assembly language code for even a simple graphical user interface (GUI). Today, with high level programming languages, just a few lines of code, which call a rich GUI library, are translated to thousands of lines of binary machine code. The instant response to the mouse movements, hides all the programming complexity that lies behind one simple, almost instinctive gesture.
Of course we are looking at this backwards – like archeologists digging down into the past. In the history of computing it took five or six decades to evolve: beginning with punched cards and binary code. In the 1970s programming was still done close to the CPU with assembly code and later languages like Fortran and C. As higher level languages emerged, such as Python, Ruby and GO, productivity increased massively.
This evolution – from very low-level hardware-centric instructions, through higher-level commands, towards something closer to natural human expressions of intent – is almost universal in the development of industrial and IT processes.
A good example is in the development of chips themselves. Originally chips were designed at a very low level by literally drawing a picture of the transistor devices layer by layer, with so call Rubylith masking film. Within a few years this process was replaced by drawing the chip devices on a graphic computer workstation. This computerised "polygon-pushing" greatly accelerated chip design and efficiency, but still required engineers that could think at the transistor device level. Chip development migrated to designing with higher level schematics and using automatic tools to generate the transistor polygons.
This was followed in the 1990's by even higher level hardware description languages like Verilog and VHDL that were then synthesised to gates and automatic place and route tools used to connect them. Today even higher-level abstractions of chip functionality can be auto-magically mapped to the low-level drawings that define the billions of transistors in a state-of-the-art chip.
Along the way, this progress hides the original knowledge about transistors and polygon devices beneath the higher level descriptions. The low level devices are now understood only by a few of the 'gray-beard' engineers in the organisation.
To describe these development stages as "evolution" makes it sound too smooth and easy because, in practice, each step-change results in severe industry dislocations, generating whole new companies to compete for space in each emerging market landscape. More a revolution than an evolution.
The new data center
Right now we are facing such a revolution in the very nature of how business is being transacted. The explosion of digital data from a wide variety of sources requires that companies rethink the way they run their businesses, to capture, analyse, and monetise this data. This represents a shift from a compute-centric programming to data-centric way of thinking - a revolution that could endanger companies that fails to adapt – as the following piece of history suggests.
In 2007 Nokia invested in the booming SatNav market by acquiring Navitech, a company that had invested significant capital to deploy nearly five million traffic cameras across Europe. A smart move, as a navigation system that kept up to date with real time traffic conditions would offer a major competitive advantage over static maps.
In the same year, an Israeli company called Waze started, with a similar objective – except that Waze gathered its traffic data without installing millions of traffic sensors, but by using the GPS sensors already present in advanced mobile phones to harvest traffic movement data and upload it to the Waze data center. By 'crowd-sourcing' this readily available data, within a few years Waze had tens of millions of free mobile sensors deployed, while Nokia had shrunk to less than the buying price of Navitech, and Waze was snapped up by Google.
That story illustrates a fundamental shift: from going out to collect data, to enabling data to pour in like a tropical monsoon. The result of such developments, and the spread of IoT connected devices, is a growing deluge of unstructured data, from a diverse range of sources; and the need to find ways to mine such data, find hidden relationships, to satisfy business-driven intentions as diverse as transcribing speech, recognising faces, or analysing market trading patterns.
A little problem - data growth is outstripping processing growth
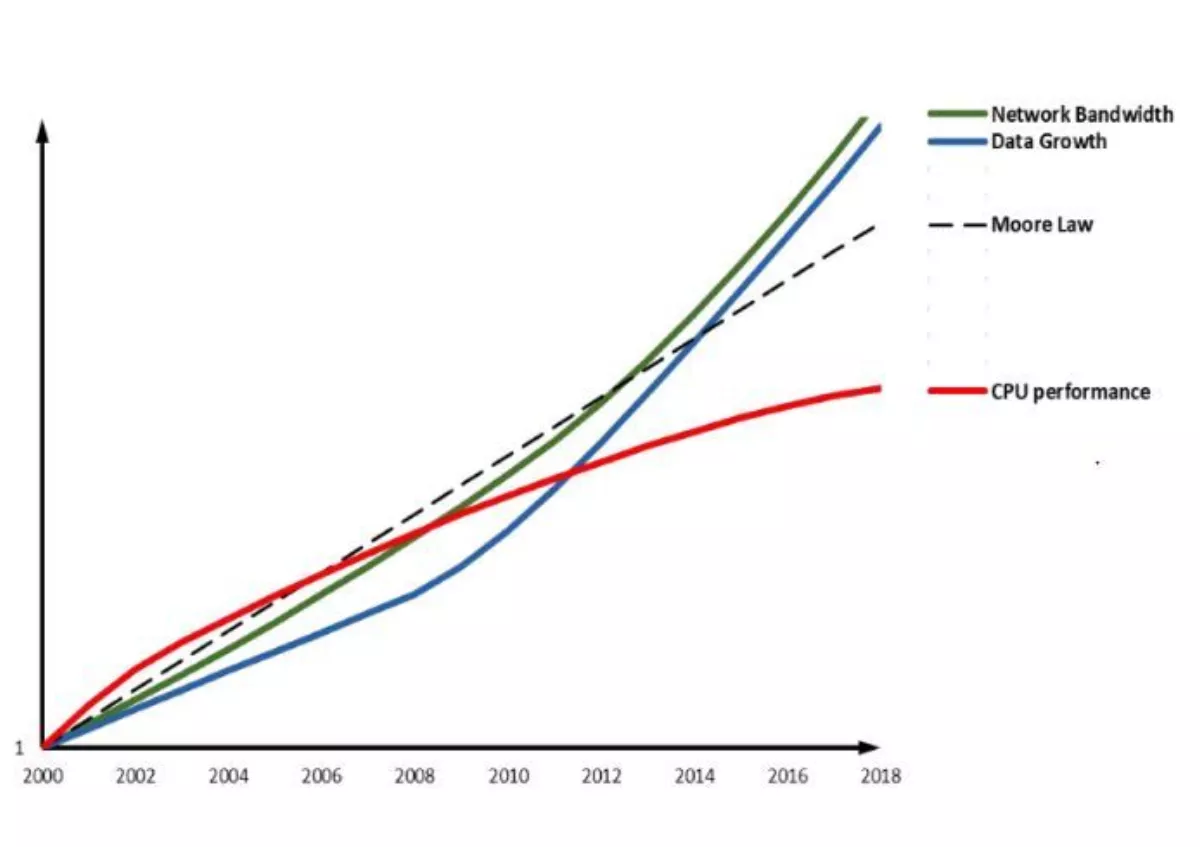
Unfortunately, this explosion in data comes at precisely the same time that the historical improvements in processing power needed to analyse it, is slowing down. In Fig 1 the blue line, Data Growth, accelerates upwards with the rise of the digital transformation and IoT data collection. There is also a straight line representing the linear growth in processing power that was historically promised by Moore's Law, and a red line showing the actual falling off in CPU performance as we approach the limits of silicon device physics.
On the other hand, notice how the green line, representing Network Bandwidth in Fig 1, tracks the surge in Data Growth. This illustrates where the future is heading. Instead of building performance by simply adding more, faster servers, today's data centers are scaling out – requiring architects to pay more attention to network performance, using faster Ethernet and, above all, optimising the networks' efficiency.
For example we worked with Oracle on their clustered database system, migrating from 10Gig speeds to 25 and 100 Gig Ethernet. The resulting performance boost was not just ten-fold, but 50-fold – thanks to more efficient use of resources.
It is becoming increasingly hard to process this flood of data using old CPU-centric approaches, where humans create algorithms and write programs able to sort and analyse structured data. Faced with a deluge of unstructured data from a variety of sources, the solution is to combine automation, artificial intelligence, and machine learning, and transform so that the data actually programs the machine.
A recent example is Google's AlphaZero software for games like Chess and Go. Unlike earlier game programs that first needed to be programmed with strategies on how to win the game, AlphaZero just got the basic rules and then started playing. After a few million games it not only worked out its own strategies, but quickly was able to beat all other programs that had been 'programmed' with the best strategies that human minds could imagine. In essence the data wrote a program implementing better strategies than any human could devise.
Let the network share the load
So, it's not just about how fast you move the data along the wires. The secret is to process the data as it moves. Instead of concentrating all the system's intelligence at the server end points, we distribute intelligence across the network in the form of SmartNICs (Network Interface Cards). With computational units in every switch, we can do data aggregation on the fly. Not only making the network super-efficient but also shedding much of the NFV (network function virtualisation) overhead from the server CPU and freeing cycles to run the applications they are meant to serve.
Even better this intelligent network offload actually improves security. In a conventional system running software security, once malware has penetrated a server, it is able to penetrate the security policy itself, and so take over the whole data center. To protect the infrastructure, it is critical to isolate the attacker from the security policy. Thus running security policy on the SmartNIC prevents attackers from defeating the protection.
Intelligence in the network allows security policy to be hosted on the NIC with its own operating system – keeping it distinct from the application servers and totally segregating the infrastructure computing and the application computing tiers. The compute server and the infrastructure server can be independently upgraded. This is both more secure and much more efficient.
Ride the revolution
The growth in data is manifest and analysts forecast project that this surge in data will continue. This data will either clog up a conventionally designed system or be mined for profitable business intelligence. To achieve the latter we can no longer rely on human-designed algorithms and old-school compute models, we must ride the revolution that combines massive flows of data with automated machine learning.
Traditional data center technology will never be able to handle this double demand on network bandwidth plus compute capacity. The only way forward is to bring intelligence into the network itself.